

In the analysis of single-cell RNA-sequencing (scRNA-seq) data, how to effectively and accurately identify cell clusters from a large number of cell mixtures is still a challenge. Low-rank representation (LRR) method has achieved excellent results in subspace clustering. But in previous studies, most LRR-based methods usually choose the original data matrix as the dictionary. In addition, the methods based on LRR usually use spectral clustering algorithm to complete cell clustering. Therefore, there is a matching problem between the spectral clustering method and the affinity matrix, which is difficult to ensure the optimal effect of clustering. Considering the above two points, researchers at the Qufu Normal University propose the DLNLRR method to better identify the cell type. First, DLNLRR can update the dictionary during the optimization process instead of using the predefined fixed dictionary, so it can realize dictionary learning and LRR learning at the same time. Second, DLNLRR can realize subspace clustering without relying on spectral clustering algorithm, that is, they can perform clustering directly based on the low-rank matrix. Finally, the researchers carry out a large number of experiments on real single-cell datasets and experimental results show that DLNLRR is superior to other scRNA-seq data analysis algorithms in cell type identification.
The DLNLRR algorithm framework
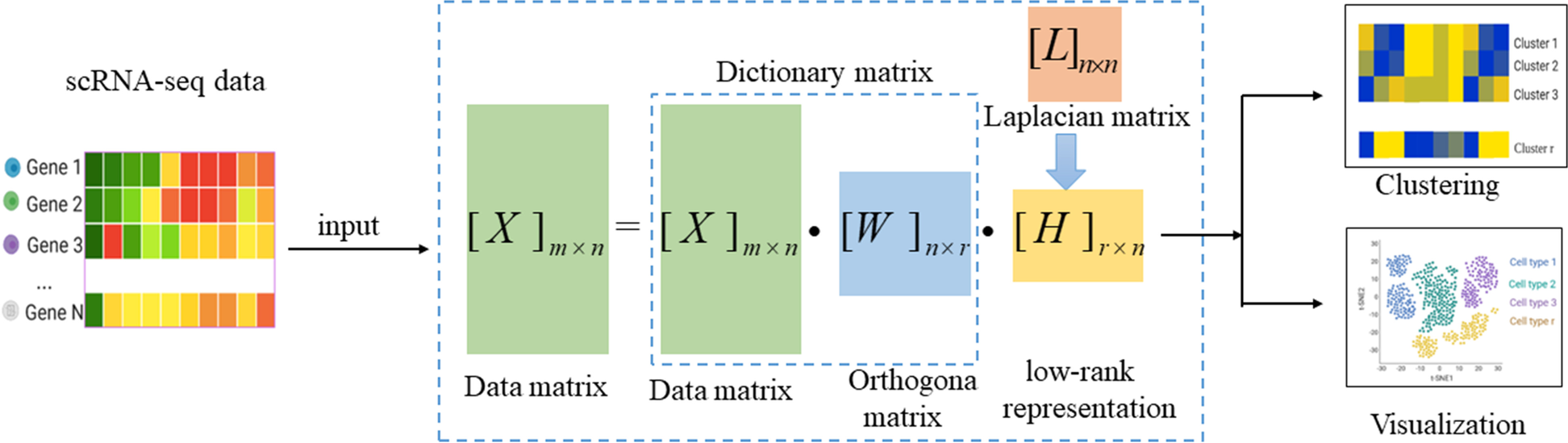
Wang J, Zhang N, Yuan S, Shang J, Dai L, Li F, Liu J. (2022) Non-negative low-rank representation based on dictionary learning for single-cell RNA-sequencing data analysis. BMC Genomics 23(1):851. [article]


